|
Building Low Latency Apps Virtual Masterclass (Sponsored)
Get battle-tested tips from Pekka Enberg, Author of Latency and Turso co-founder
 |
Latency lurks in every layer of a distributed system. In this masterclass you’ll learn proven strategies to eliminate bottlenecks across the stack — from the application layer down to the database.
After this free 2-hour masterclass, you will know how to:
Spot, understand, and respond to latency, across your whole stack
Tackle often-overlooked causes of database latency
Evaluate when (and when not) to use caching for latency reduction
All attendees will get early access to Pekka’s new Latency book.
Designed for teams building performance critical applications, this event offers practical methods for battling P99 percentiles. Attendees will walk away with a holistic approach, including techniques that intersect many areas of software engineering.
Disclaimer: The details in this post have been derived from the official documentation shared online by the Reddit Engineering Team. All credit for the technical details goes to the Reddit Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Push notifications carry a double-edged sword in the design of any product. Done well, these notifications reconnect users with content they care about. Done poorly, they turn into noise, leading users to mute them entirely or uninstall the app. Striking the right balance requires a precise and scalable system that understands what matters to each user and when it makes sense to interrupt them.
Reddit’s notification recommender system handles this problem at scale.
It evaluates millions of new posts daily and decides which ones should be sent as personalized notifications to tens of millions of users. Behind each decision is a pipeline that combines causal modeling, real-time retrieval, deep learning, and product-driven reranking.
In this article, we understand how that pipeline works. It walks through the key components (budgeting, retrieval, ranking, and reranking) of the pipeline and highlights the trade-offs at each stage.
Some key features of the system are as follows:
It operates using a close-to-real-time pipeline.
Driven by asynchronous workers and queues.
Shares core components with other ML and ranking systems at Reddit.
Aims for low latency and high freshness of recommendations.
The system has evolved significantly, but the core goal remains unchanged: deliver timely, relevant notifications that drive engagement without overwhelming the user.
The Overall Architecture
The notification pipeline processes millions of posts daily to decide which ones to deliver as push notifications.
It’s structured as a series of focused stages, each responsible for narrowing and refining the candidate set.
Budgeting sets the daily limit for how many notifications to send to each user, balancing engagement with fatigue.
Retrieval pulls a shortlist of potentially interesting posts using fast, lightweight methods.
Ranking scores these candidates using a deep learning model trained on user interactions like clicks, upvotes, and comments.
Reranking adjusts the final order based on business goals—boosting certain content types or enforcing diversity.
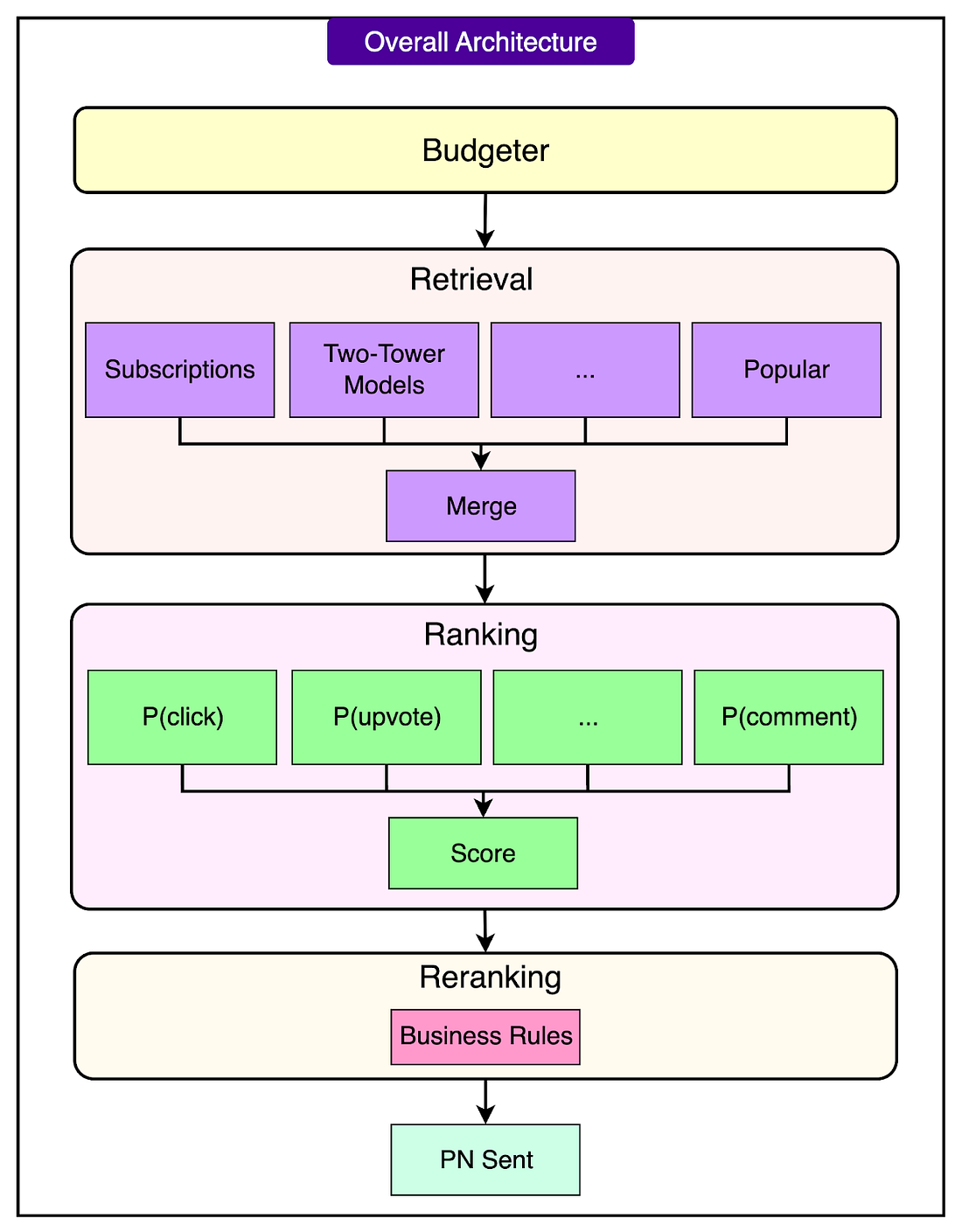 |
The pipeline runs on a queue-based asynchronous infrastructure to ensure timely delivery, even at massive scale.
Budgeter
The first decision the system makes each day is how many notifications a user should receive.
Notification fatigue isn’t just a UX nuisance, but a permanent loss of reach. Once a user disables notifications, there’s rarely a path back. The system treats this as a high-cost failure. The goal is to maximize engagement without making things annoying.
Not every user gets the same treatment. The budgeter estimates how each additional notification might affect user behavior. Push too hard, and users disable notifications or churn. Hold back too much, and the system misses opportunities to re-engage them. The balance between the two is modeled using causal inference and adaptive scoring.
The system uses a causal modeling approach to weigh outcomes:
Positive outcomes include increased activity such as clicking the notification, browsing the app, and interacting with content.
Negative outcomes include signs of churn (long gaps in usage) or outright disabling of push notifications.
Often, basic correlation (for example, “this user got 5 notifications and stayed active”) doesn’t reveal the whole picture. Instead, the system uses past user behavior to estimate how different notification volumes affect outcomes such as staying active versus dropping off. This approach, known as causal modeling, helps avoid overfitting to noisy engagement data. It doesn’t just look at what happened, but tries to estimate what would have happened under different conditions.
To do this effectively, the team builds unbiased datasets by intentionally varying notification volumes across different user groups. These variations are used to estimate treatment effects and how different budgets affect long-term engagement patterns.
At the start of each day, a multi-model ensemble estimates several candidate budgets for a user. Each model simulates outcomes under different conditions: some more conservative, some more aggressive.
The system then selects the budget that optimizes a final engagement score. That score reflects both expected gains (clicks, sessions) and expected risks (disablement, drop-off). If the models indicate that an extra PN would yield a meaningful value, the budget is increased up to that point. If not, the system holds the line. The result is a dynamic, per-user push strategy that reflects actual behavioral data.
See the diagram below: