|
Stream Smarter with Amazon S3 + Redpanda (Sponsored)
 |
Join us live on November 12 for a Redpanda Tech Talk with AWS experts exploring how to connect streaming and object storage for real-time, scalable data pipelines. Redpanda’s Chandler Mayo and AWS Partner Solutions Architect Dr. Art Sedighi will show how to move data seamlessly between Redpanda Serverless and Amazon S3 — no custom code required. Learn practical patterns for ingesting, exporting, and analyzing data across your streaming and storage layers. Whether you’re building event-driven apps or analytics pipelines, this session will help you optimize for performance, cost, and reliability.
Disclaimer: The details in this post have been derived from the details shared online by the Uber Engineering Team. All credit for the technical details goes to the Uber Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
For a company operating at Uber’s scale, financial decision-making depends on how quickly and accurately teams can access critical data. Every minute spent waiting for reports can delay decisions that impact millions of transactions worldwide.
Uber Engineering Team recognized that their finance teams were spending a significant amount of time just trying to retrieve the right data before they could even begin their analysis.
Historically, financial analysts had to log into multiple platforms like Presto, IBM Planning Analytics, Oracle EPM, and Google Docs to find relevant numbers. This fragmented process created serious bottlenecks. Analysts often had to manually search across different systems, which increased the risk of using outdated or inconsistent data. If they wanted to retrieve more complex information, they had to write SQL queries. This required deep knowledge of data structures and constant reference to documentation, which made the process slow and prone to errors.
In many cases, analysts submitted requests to the data science team to get the required data, which introduced additional delays of several hours or even days. By the time the reports were ready, valuable time had already been lost.
For a fast-moving company, this delay in accessing insights can limit the ability to make informed, real-time financial decisions.
Uber Engineering Team set out to solve this. Their goal was clear: build a secure and real-time financial data access layer that could live directly inside the daily workflow of finance teams. Instead of navigating multiple platforms or writing SQL queries, analysts should be able to ask questions in plain language and get answers in seconds.
This vision led to the creation of Finch, Uber’s conversational AI data agent. Finch is designed to bring financial intelligence directly into Slack, the communication platform already used by the company’s teams. In this article, we will look at how Uber built Finch and how it works under the hood.
 |
What is Finch?
To solve the long-standing problem of slow and complex data access, the Uber Engineering Team built Finch, a conversational AI data agent that lives directly inside Slack. Instead of logging into multiple systems or writing long SQL queries, finance team members can simply type a question in natural language. Finch then takes care of the rest.
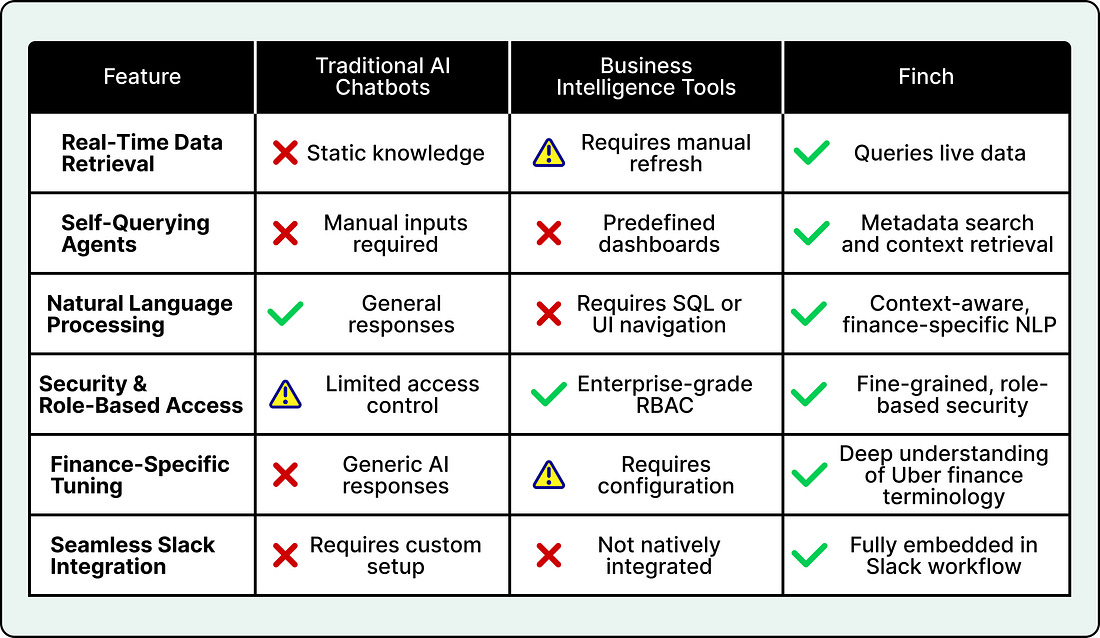
See the comparison table below that shows how Finch stands out from other AI finance tools.
 |
At its core, Finch is designed to make financial data retrieval feel as easy as sending a message to a colleague. When a user types a question, Finch translates the request into a structured SQL query behind the scenes. It identifies the right data source, applies the correct filters, checks user permissions, and retrieves the latest financial data in real time.
Security is built into this process through role-based access controls (RBAC). This ensures that only authorized users can access sensitive financial information. Once Finch retrieves the results, it sends the response back to Slack in a clean, readable format. If the data set is large, Finch can automatically export it to Google Sheets so that users can work with it directly without any extra steps.
For example, the user might ask: “What was the GB value in US&C in Q4 2024?”
Finch quickly finds the relevant table, builds the appropriate SQL query, executes it, and returns the result right inside Slack. The user gets a clear, ready-to-use answer in seconds instead of spending hours searching, writing queries, or waiting for another team.
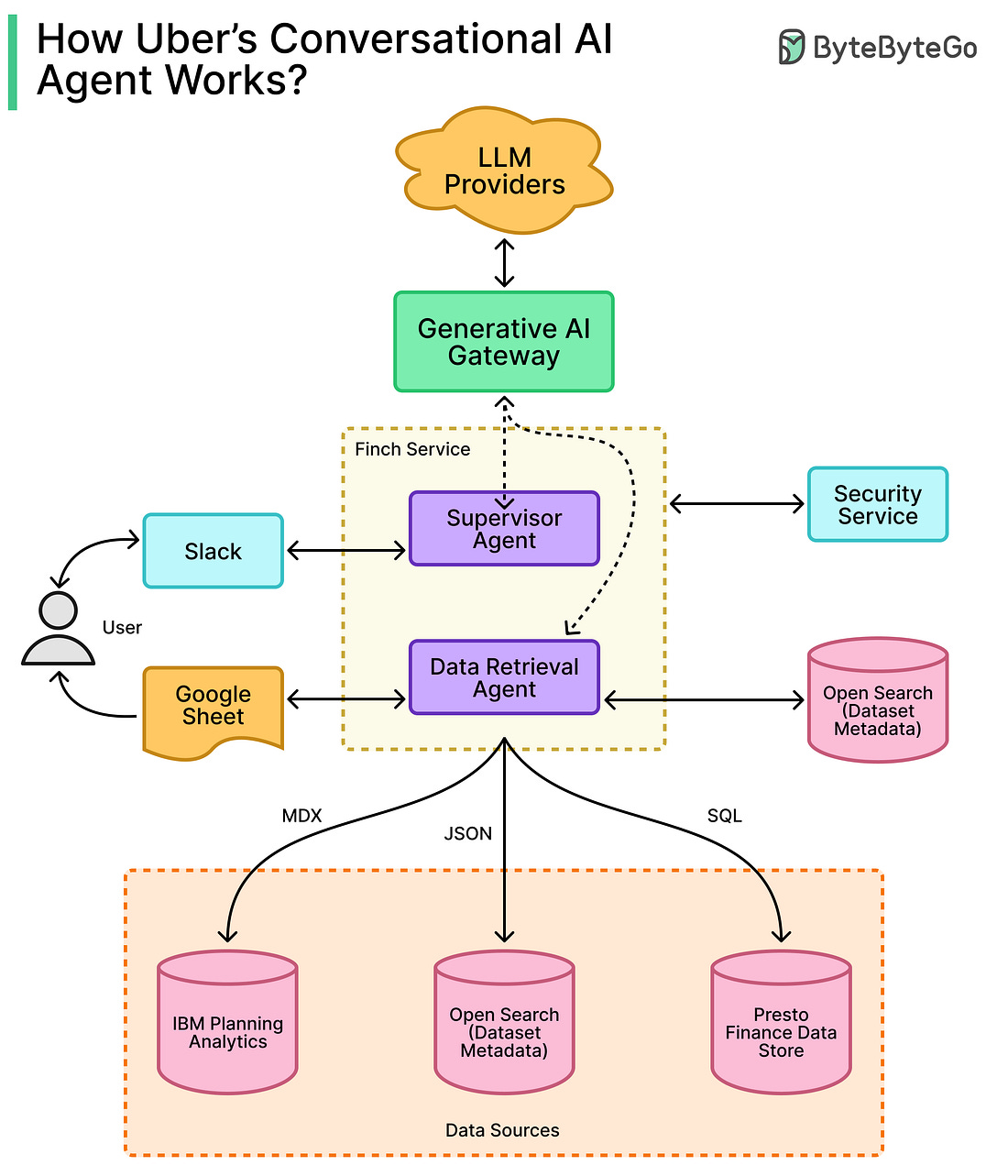
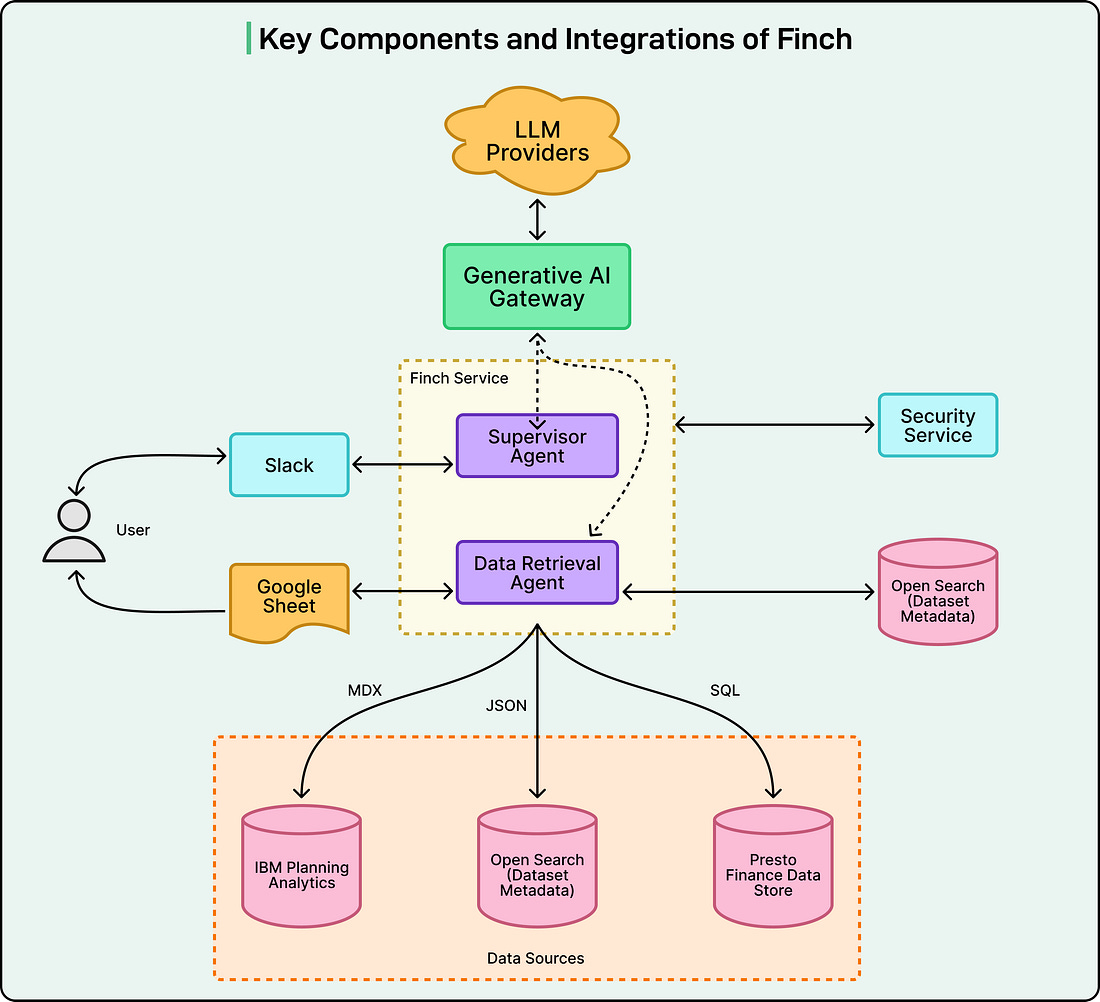
Finch Architecture Overview
The design of Finch is centered on three major goals: modularity, security, and accuracy in how large language models generate and execute queries.
Uber Engineering Team built the system so that each part of the architecture can work independently while still fitting smoothly into the overall data pipeline. This makes Finch easier to scale, maintain, and improve over time.
The diagram below shows the key components of Finch:
 |
At the foundation of Finch is its data layer. Uber uses curated, single-table data marts that