Hey, this is the 7th module of the TimescaleDB course, and it's the last chapter about performance. With continuous aggregates from the last module, you can precompute all your statistics so they always take just a few milliseconds to execute - independently of their size! But you probably failed at making a continuous aggregate for
avg(column)
because you can't combine two values.
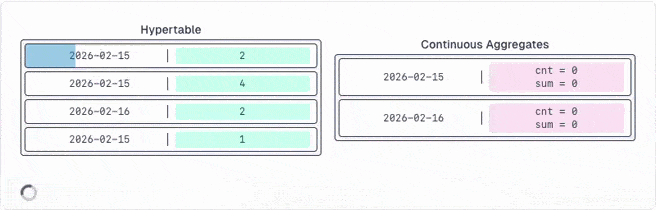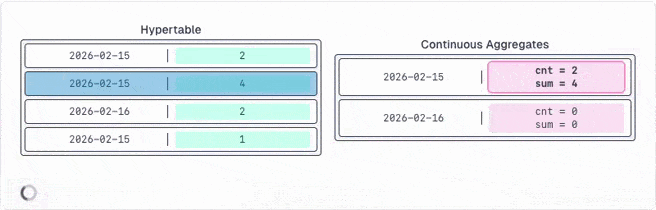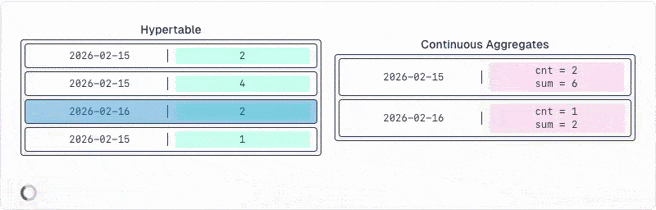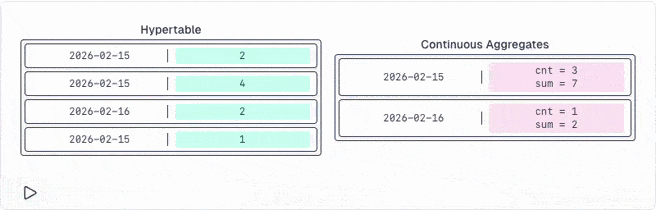
The problem is that any database processes all rows, constantly updates an internal state and then calculates the final value you receive. But the internal state is never exposed. However, it would be helpful for you to re-aggregate the results of your continuous aggregates.
TimescaleDB identified this problem and provides a new set of aggregate functions that expose the internal state as their final value. So you can save those values into continuous aggregates.
The best part is that you can re-aggregate (rollup) this state infinitely. And rolled up states can be re-aggregated as well.
But hyperfunctions do more than simply re-export standard aggregation functions in a new way. They are optimized to handle infinitely large datasets: Some aggregations must keep all data to calculate their final value which is obviously a problem if you have huge databases. So TimescaleDB added approximate aggregations that only use a tiny bit of storage and produce a value that is very near to the exact value, but not identical. It is a powerful optimization
to trade a tiny bit of accuracy for big performance gains.
That's a rough overview of the course's chapter but it describes the main idea. Learn about hyperfunctions and how they enable you to pre-compute more statistics for your continuous aggregates. If that sounds interesting to you, please take a look at it and let me know what you think!
I hope you learn a lot
Tobias