|
Your cache isn’t the problem. How you’re using it is. (Sponsored)
 |
If your cache only speeds up a few endpoints, your cache strategy is too narrow.
That model doesn’t scale. It creates stale data, extra complexity, and more load on your database than you think.
Modern systems treat cache differently. It’s seen as a real-time data layer that’s structured, queryable, and always in sync with source data.
This guide walks through how teams make that shift—from basic key-value storage to a cache that can actually carry production workloads.
Inside, you’ll learn:
How to cut database pressure without adding more infrastructure
How to serve more queries at sub-millisecond latency
How to keep data fresh without stitching together brittle pipelines
If you’re running into performance or cost limits, this guide is for you.
Datadog’s Metrics Summary page had a problem. For one customer, every time someone loaded the page, the database had to join a table of 82,000 active metrics with 817,000 metric configurations. The p90 latency hit 7 seconds. Every time a user clicked a filter, it triggered another expensive join.
The team tried the usual fixes, such as query optimization, indexing, and tuning. However, the problem wasn’t the query. They were asking a database designed for transactions to do the job of a search engine. Fixing that one page set off a chain of architectural decisions that didn’t just solve the performance issue. It led Datadog to fundamentally redefine how data replication works across its entire infrastructure.
In this article, we will look at how Datadog implemented the changes and the challenges they faced.
Disclaimer: This post is based on publicly shared details from the Datadog Engineering Team. Please comment if you notice any inaccuracies.
The Database Was Simply Doing the Wrong Job
Datadog operates thousands of services, many of them backed by a shared Postgres database. For a long time, that shared database was the right call. Postgres is reliable, well-understood, and cost-effective at small to medium scale. However, as data volumes grew, the cracks started to show, and the Metrics Summary page was just the most visible symptom.
The team’s first instinct was to optimize the database. They tried adjusting join order, adding multi-column indexes, and using query heuristics based on table size. None of it held up and there were several issues:
Disk and index bloat slowed inserts and updates.
VACUUM and ANALYZE operations added maintenance overhead.
Memory pressure drove up I/O wait times.
Monitoring with Datadog’s own APM confirmed that these queries were consuming a disproportionate share of system resources, and getting worse as the data grew. By the time multiple organizations crossed the 50,000-metrics-per-org threshold, the warning signs were everywhere, such as slow page loads, unreliable filters, and mounting operational overhead.
See the diagram below:
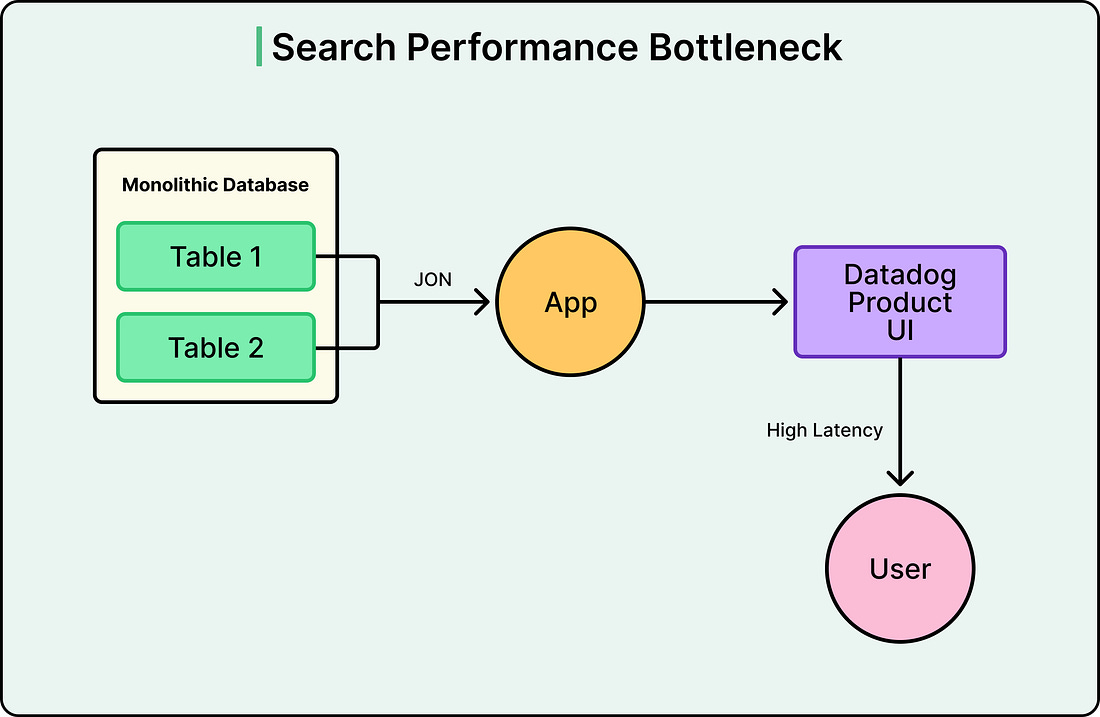 |
Postgres was being asked to do two fundamentally different jobs at once. OLTP workloads are what relational databases are designed for. However, real-time search with filtering across massive denormalized datasets is a completely different workload, one that search engines like Elasticsearch are purpose-built to handle.
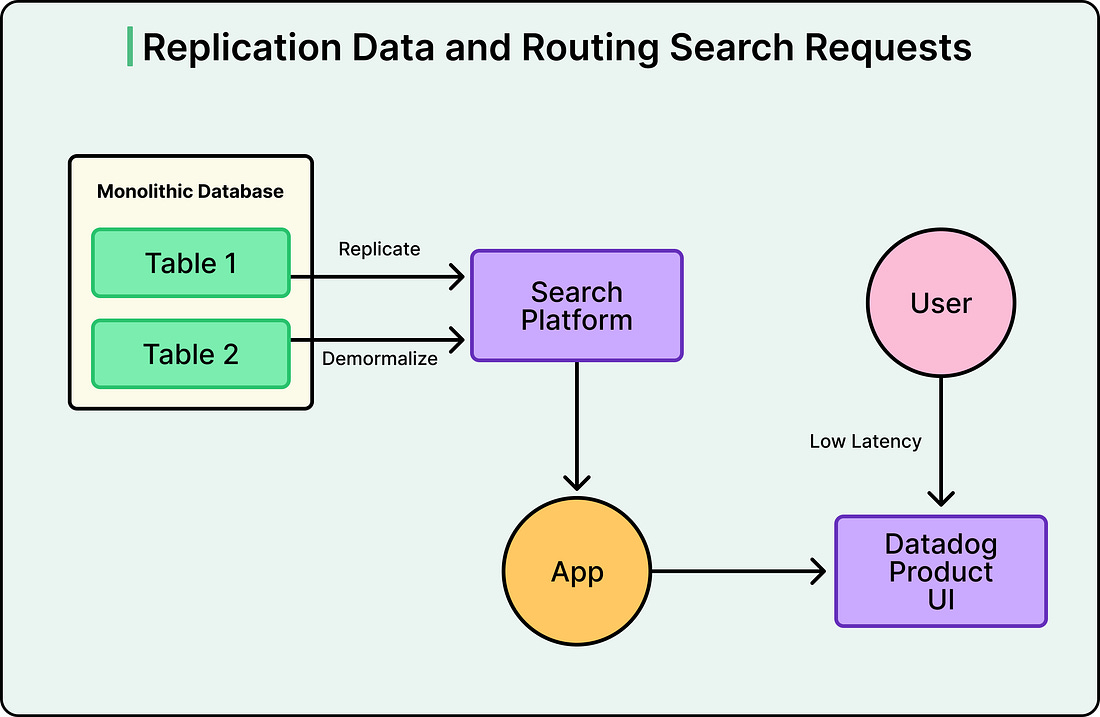
Therefore, instead of making Postgres better at searching, Datadog stopped making it search at all. They replicated data from Postgres into a dedicated search platform, flattening the relational structure into denormalized documents along the way. The mechanism behind this is Change Data Capture, or CDC.
Postgres already records every change (every insert, update, and delete) in its Write-Ahead Log, or WAL. This log exists primarily for crash recovery, but it can also be read by external tools. Datadog used Debezium, an open-source CDC tool, to read that log and stream changes into Kafka, a durable message broker. From Kafka, sink connectors pushed the data into the search platform.
The advantage of this approach is that the application itself didn’t need to change how it wrote data. It still writes to Postgres as before. However, search queries now hit the search platform instead, which was purpose-built for exactly that workload.
See the diagram below:
 |
Why Async?
Before scaling that pattern, the team faced a key design choice: synchronous or asynchronous replication.
In synchronous replication, the primary database doesn’t confirm a write to the application until every replica has acknowledged receiving it. This guarantees strong consistency, meaning every system has the same data at all times. But it’s slow. If one replica is across the network or temporarily unhealthy, the entire write pipeline stalls waiting for confirmation. One slow consumer becomes a bottleneck for everything.