|
New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)
 |
Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
Every time you buy something online from a Stripe-powered business, a machine learning model evaluates over 1,000 signals about your transaction and decides in under 100 milliseconds whether to let it through.
Across billions of legitimate payments, it reaches the correct verdict 99.9% of the time. The system that delivers those numbers, however, looks entirely different from what Stripe originally built.
The architecture has been overhauled multiple times, and one of the most important upgrades required removing a component the team knew was actively improving accuracy, because keeping it was holding back everything else the team wanted to do.
For reference, online payment fraud occurs in roughly 1 out of every 1,000 transactions. That rarity makes fraud detection a difficult machine learning problem because the system has to surface a small number of fraudulent payments from a massive volume of legitimate ones, and it has to do this quickly and cheaply on every single transaction.
In this article, we will look at how Stripe’s Radar does this effectively and the architectural decisions the team took while building it.
Disclaimer: This post is based on publicly shared details from the Stripe Engineering Team. Please comment if you notice any inaccuracies.
Why Stripe Removed the Component That Was Making Radar Better
Stripe began with relatively simple ML models like logistic regression (a statistical method that predicts the probability of an outcome based on input variables). Over time, as the Stripe network grew and ML technology advanced, they moved to more complex architectures. Each jump produced an equivalent leap in model performance.
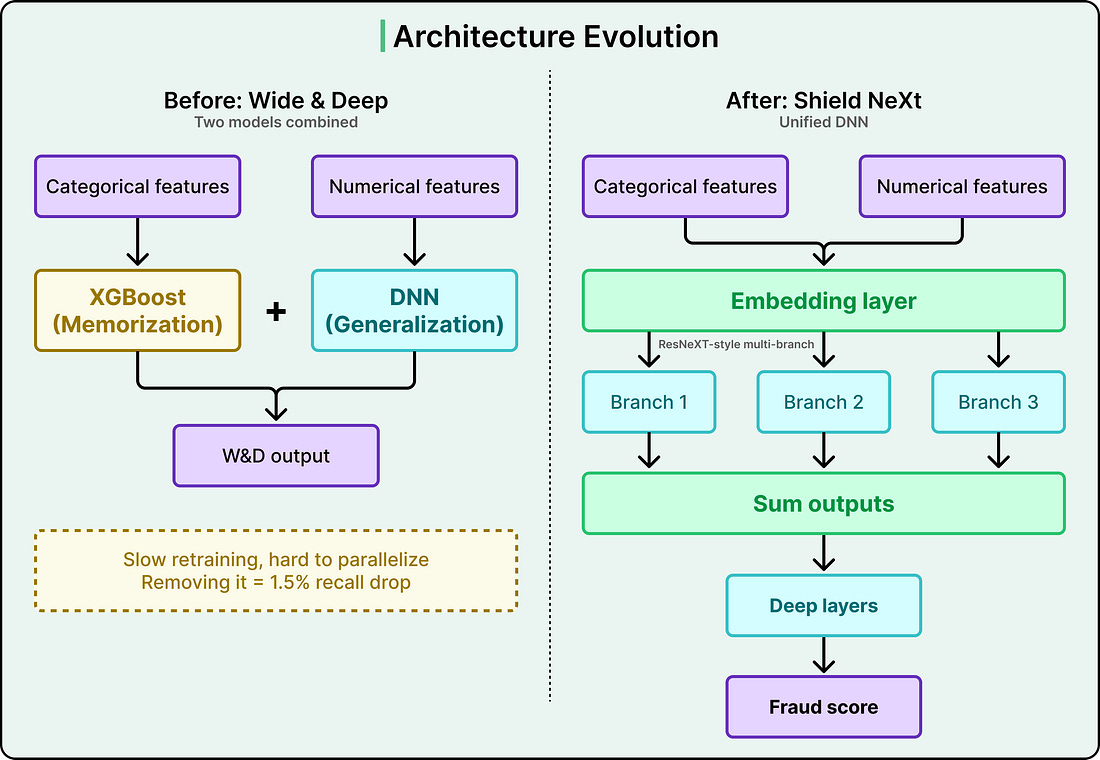 |
The architecture preceding the current one was called Wide & Deep. It combined two models into an ensemble.
The “wide” component was XGBoost, a gradient-boosted decision tree that works by combining many small decision trees into one powerful predictor. XGBoost excelled at memorization, meaning it was strong at recognizing specific patterns and feature correlations it had encountered in training data.
The “deep” component was a deep neural network (DNN) that excelled at generalization, meaning it could learn abstract concepts like “unusual payment velocity on a card” and apply them to entirely new situations it had never seen before.
Together, the two components worked well. But XGBoost was creating operational bottlenecks. It was hard to parallelize, which meant retraining the combined model was slow. It was incompatible with advanced ML techniques Stripe wanted to adopt, like transfer learning that involves using knowledge gained from one task to improve performance on a different but related task, and embeddings. And it was also limiting how quickly the many engineers working on Radar each day could experiment with new ideas.
Simply dropping XGBoost would have caused a 1.5% drop in recall, meaning 1.5% more fraud would go undetected. That was an unacceptably large regression in performance. The value XGBoost provided was real and measurable, so it had to be replicated within a new architecture rather than just discarded.
Stripe’s solution drew inspiration from a research architecture called ResNeXt.
The core idea, sometimes called “Network-in-Neuron,” splits computation into multiple distinct branches, where each branch functions as a small neural network on its own. The outputs from all branches are summed to produce a final result. This multi-branch approach enriches feature representation along a new dimension, and it achieves this more effectively than the brute-force approach of simply making a DNN wider or deeper, which risks overfitting (the model memorizing random noise rather than learning real patterns).
The resulting architecture, internally called Shield NeXt, reduced training time by over 85%, bringing it to under two hours. Experiments that previously required overnight jobs could now run multiple times in a single working day. Stripe is now exploring techniques that this architectural shift made possible, including multi-task learning, where a single model is trained to handle several related objectives simultaneously.
[Live on May 6] Stop babysitting your agents (Sponsored)
 |