|
New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)
 |
Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
Snapchat decides what to show you in roughly 100 milliseconds. In that window, the system has to retrieve a few hundred candidate videos from a corpus of millions, fetch dozens of features about the user and dozens about each candidate, run a deep learning model over every pair, and rank the results. Now consider how this scales when 477 million people open the app every day.
The interesting question is how the system stays fast at this scale. The deeper question is what shape the system has to have to be fast at all.
Snapchat started in 2011 as an ephemeral messaging app where photos disappeared after a few seconds, and it has since grown into a full social platform with Discover, Spotlight, augmented reality lenses, friend suggestions, and an ad business that funds most of the company. Snap reported 946 million monthly active users in late 2025, with about 474 million of them opening the app every day. India is the largest market with over 214 million users, followed by the United States with around 104 million, while France, the Gulf countries, and other regions make up the rest of a global footprint that spans every major social media market.
For Snap, machine learning is closer to the product itself than a feature on top of it. Every session forces the system to make four kinds of decisions.
The first is which content should appear in your Discover and Spotlight feeds.
The second is which ads should win the auction for your attention.
The third is which people should appear in your friend suggestions.
The fourth is which AR lenses and effects should surface for you.
Each decision is shaped by an ML model, each one happens in milliseconds, and each one can be wrong in expensive ways. A bad ad ranking costs revenue directly, while a bad recommendation costs engagement, which costs future revenue.
All of this runs on a single platform called Bento. In this article, we’ll look at how the Snap engineering team built Bento and the challenges they faced along the way.
Disclaimer: This post is based on publicly shared details from the Snap Engineering Team. Please comment if you notice any inaccuracies.
The Shape of a Ranking Workload
A typical web request is roughly symmetric. One request arrives, the server queries a database, builds a response, and sends it back. The shape is one-to-one.
A ranking request is asymmetric. One user opens the app, and the platform has to decide what to show them out of millions of options. Internally, this single request expands into hundreds or thousands of pairs of (user, candidate) that each need a score from a model. After scoring, the system ranks the candidates and returns the top few to the user. A single request comes in, hundreds or thousands of model evaluations happen, and a short ranked list goes back out.
This expansion is what shapes Bento. Almost every architectural decision in the platform is an answer to the question of how to absorb this fanout.
In practice, the work is split across two stages.
The first stage is retrieval, where cheap models filter the full corpus down to a few hundred or thousands of candidates worth scoring.
The second stage is ranking, where expensive models score those candidates carefully and produce the final order.
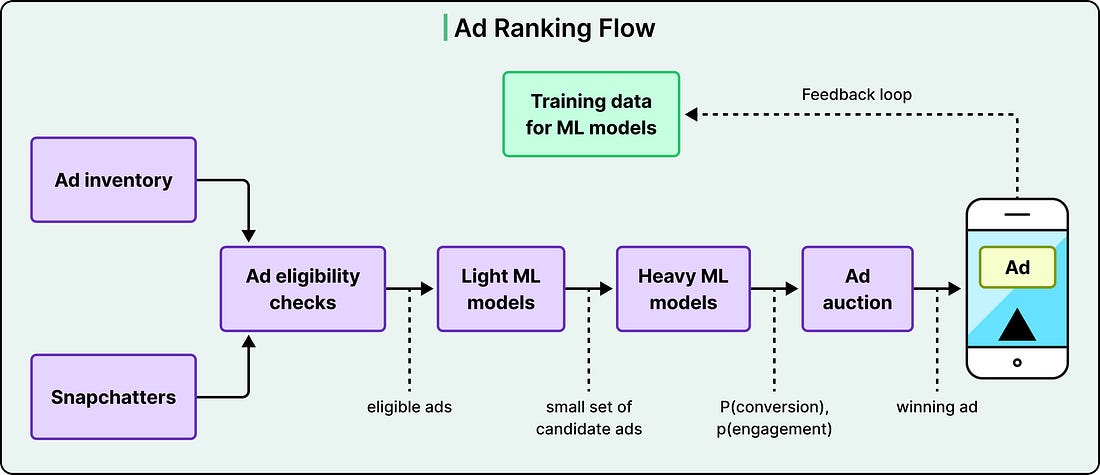 |
Snap’s ad ranking system follows this pattern explicitly. Light models filter the eligible ad inventory, heavy models predict the probability of conversion and engagement, an auction picks the winner, and the winning ad is served. The user’s response to that ad, whether they click, dismiss, or watch, then flows back into the training data.
The math gets large quickly. If hundreds of millions of users each trigger a few ranking requests per session, and each request scores hundreds of candidates, the total prediction volume crosses a billion per second. Snap reports that exact number, along with 1 TB per second of feature reads and 10 trillion events per day flowing through the feature pipelines.
This design creates four distinct kinds of pressure on the platform:
Latency pressure comes from the simple fact that users will abandon the app if a feed takes too long to load.
Scale pressure comes from the sheer prediction volume itself.
Freshness pressure comes from the requirement that a user who just liked a video should immediately see the system respond to that signal.
Iteration pressure comes from the need for ML engineers to ship hundreds of experiments per month to keep the models competitive.
These pressures pull in different directions, since latency wants smaller models, scale wants cheaper compute, freshness wants real-time pipelines, and iteration wants flexible tooling. The point of Bento is to make all four tractable at the same time.
The platform splits cleanly into two halves. One half produces models, while the other half serves them. Almost all of the unusual engineering lives in the second half.