|
How to Track AI ROI in Real Time (Sponsored)
 |
Datadog’s guide shows you how to connect AI spend, infrastructure, and model performance into a single view, so you can catch cost spikes the moment they happen. See how Kevel cut AWS costs by up to $100,000/month after replacing reactive cost reviews with real-time visibility.
You’ll learn how to:
Break down AI costs by token, model, provider, and team
Get alerted the instant inference volume spikes or API spend exceeds budget
Correlate cost increases directly to architecture changes so root-cause analysis takes minutes
DoorDash’s customer support chatbot had a hallucination problem. Not the dramatic kind where it invents entire conversations, but the subtle, harder-to-catch kind.
For example, the chatbot would look at a customer’s order history, see a delivery status field, misread it, and then confidently suggest a refund policy that didn’t actually exist. The raw data was right there in the chatbot’s context window, the working memory where an LLM holds everything it needs to generate a response, but having too much information was making things worse.
For reference, DoorDash is one of the largest food delivery and local commerce platforms in the United States, connecting customers with restaurants and stores through a network of independent delivery drivers called Dashers.
At that scale, the company handles hundreds of thousands of support contacts every day from customers, merchants, and Dashers, making automated support not just a nice-to-have but a necessity.
The team could see the problem clearly, but fixing it was a different story. Every change they made to reduce hallucinations in one scenario risked creating new ones in another. They were stuck between two bad options. They could deploy changes to production and hope for the best, which meant risking real customer experiences. Or they could manually test dozens of conversation scenarios for every prompt change, which would take weeks and still might miss things.
This tension isn’t unique to DoorDash. It’s the fundamental challenge anyone faces when they move from traditional deterministic software to LLM-based systems. DoorDash used to run customer support on hand-built decision trees, where every change had a predictable, traceable impact. LLMs replaced that predictability with flexibility and more natural conversations, but they also introduced non-determinism, meaning the same input can produce different outputs each time.
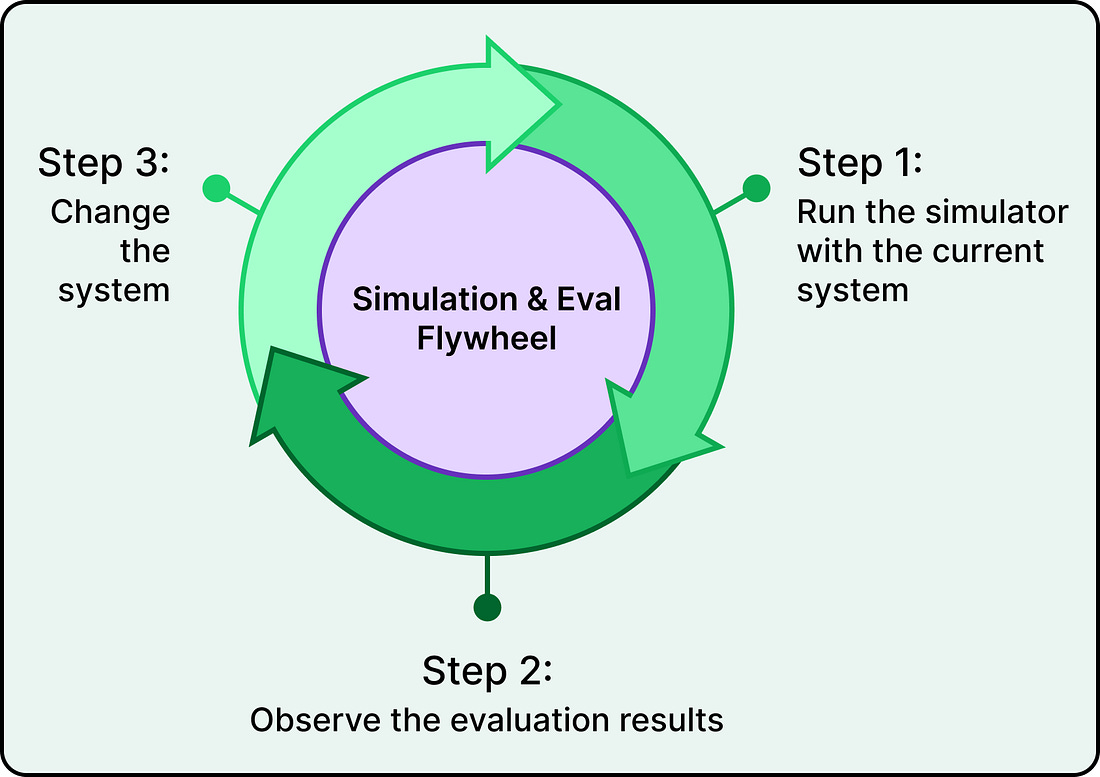
DoorDash’s answer to this problem wasn’t a better chatbot. It was a better system for improving the chatbot, something they call the simulation and evaluation flywheel. In this article, we will learn how they built this flywheel and the key takeaways.
Disclaimer: This post is based on publicly shared details from the DoorDash Engineering Team. Please comment if you notice any inaccuracies.
What the Flywheel Actually Does
The flywheel has two interconnected pieces:
The first is an offline simulator that generates realistic multi-turn customer conversations without involving any real customers.
The second is an evaluation framework that automatically grades how the chatbot performed in those conversations.
Together, they create a tight iteration loop.
 |
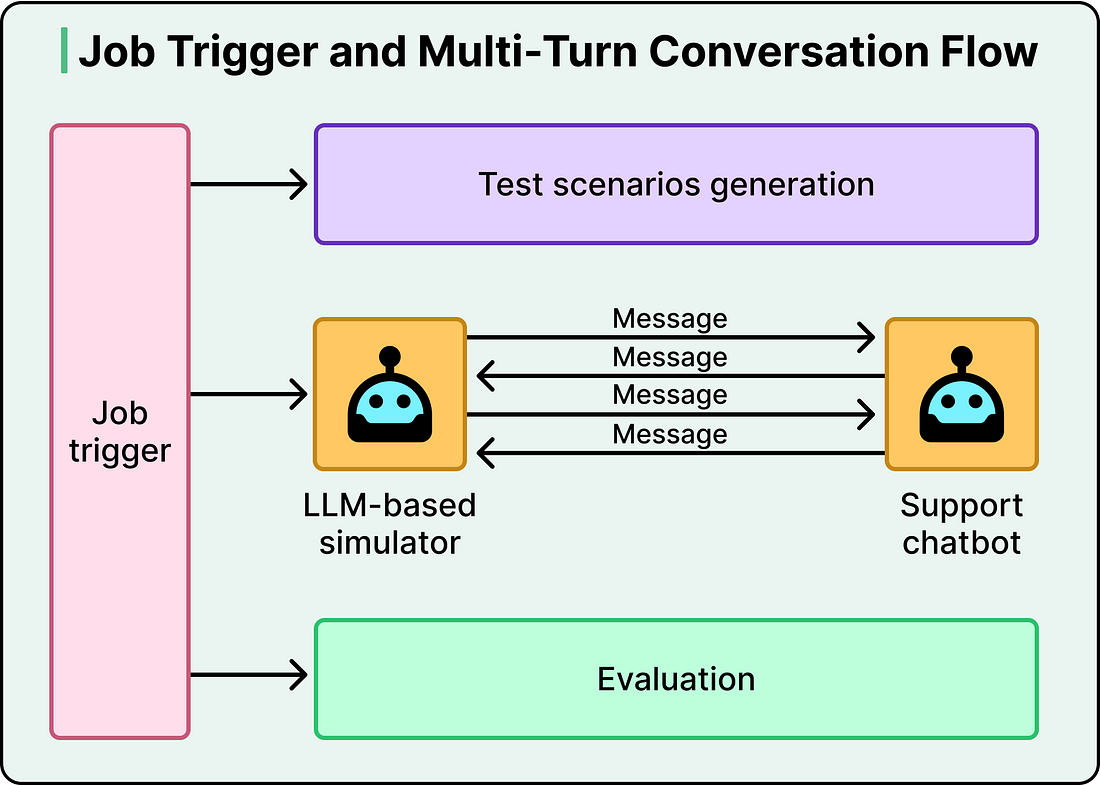
When the team notices a problem, they write an evaluation that captures the specific failure mode they want to fix. A single job trigger then orchestrates the entire pipeline end-to-end, automatically generating test scenarios from historical transcripts, running multi-turn conversations between the simulator and the chatbot, and evaluating the results.
 |
Then they modify the prompt or the system architecture, run the simulator again, and check whether the pass rate climbed. If it did, they would keep going. If it didn’t, they try something else. They repeat this cycle until the pass rate hits their exit criteria, and then they deploy with confidence that the change actually works.
The graph below shows the pass rate for no-hallucination evaluation over time
 |