|
AI writes the code. Who governs the quality? (Sponsored)
 |
AI-assisted development has changed how code gets written, but for many teams, testing and governance haven’t caught up. Tricentis AI Workspace closes that gap, giving quality engineering leaders one place to build, orchestrate, and govern AI quality agents across the SDLC, from code risk analysis and test automation to performance validation so quality decisions happen continuously, not at the end. Less errors introduced by AI-generated code, more confidence in what you’re shipping.
Discover how teams are using AI Workspace to bring structure to AI-driven development and compress delivery timelines without sacrificing confidence in business outcomes.
Apple’s most ambitious AI feature runs in about a gigabyte of memory on the iPhone. The same company runs a much larger model on its own cloud servers, and the two diverge in almost every architectural choice beyond the word “transformer” in their lineage.
The same split shows up at Google, Microsoft, and Meta, where one family of small models targets devices and a different family of large models targets data centers.
Small and large language models are different engineering responses to different constraints, and the differences begin with where each model runs, what hardware it targets, and how it was trained.
In this article, we will explore those constraints through three layers of model design, look at the tradeoffs that come with each approach, and investigate the production systems that combine both small and large models.
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
Foundations
Before we look at what makes the two classes different, it helps to be precise about what makes them the same.
Both small and large language models are transformer-based decoder models, built by stacking layers of the same basic computational block. Each block runs an attention operation, which figures out which previous tokens matter most for predicting the next one, followed by a feed-forward computation that mixes that information through a wide intermediate layer. The model repeats this block thirty or more times before producing a probability distribution over what the next token should be.
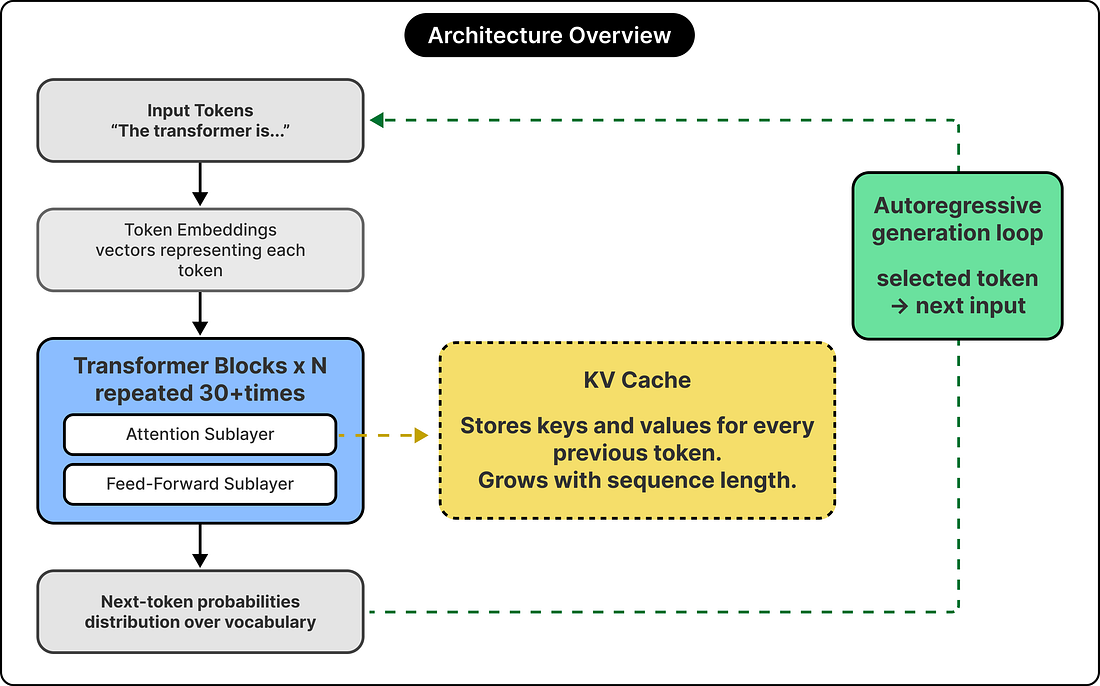 |
Both classes go through similar training stages. They start with pretraining on large text corpora, where the model learns to predict the next token across billions of examples. They typically follow with supervised fine-tuning on specific instruction patterns, and many go through reinforcement learning from human feedback, which shapes how the model handles ambiguity and stays helpful in conversation.
The size of a model refers to its number of parameters, which are the learned weights adjusted during training. A small model in 2026 typically has between half a billion and fourteen billion parameters. A large model has tens of billions to hundreds of billions of parameters, and sometimes more.
Constraints
Three constraints pull the designs of small and large models in opposite directions.
Deployment target: Where the model runs determines its memory, battery, and latency budgets.
Inference economics: Training is paid once, but serving is paid per request, which inverts the math at scale.
Training budget: Smaller budgets push teams toward efficiency through data quality and distillation rather than raw scale.
The deployment target determines everything that follows.
A model that runs on a phone has a memory budget measured in single gigabytes, a battery budget measured in milliamps, and a latency budget measured in milliseconds. A model that runs in a data center operates in a more permissive environment, with concerns around throughput, batching efficiency, and cost per request, but with an absolute resource ceiling orders of magnitude higher.
Inference economics is the second pressure.
Training a model is a one-time cost paid at the start of its life, while serving the model is a recurring cost paid every time someone uses it. For a high-volume product, the inference bill quickly dwarfs the training bill, so a team designing for high inference volume will gladly spend more training compute upfront to save inference compute across billions of requests downstream.
The training budget is the third pressure.
A frontier large model can cost tens of millions of dollars to train, while most teams working on small models operate with a small fraction of that, and the smaller budget forces choices. Those teams have to find other levers beyond raw scale, which usually means smarter training data, distillation from larger teachers, and more efficient training recipes.
These three constraints reinforce each other rather than acting in isolation. A model designed for the phone has a small inference budget per request and usually a smaller training budget too, while a model designed for the data center has the opposite profile across all three axes. The result is two distinct design regions in the same space.
 |