|
How to monitor AWS container environments at scale (Sponsored)
In this eBook, Datadog and AWS share insights into the changing state of containers in the cloud and explore why orchestration technologies are an essential part of managing ever-changing containerized workloads.
Learn more about:
Strategies for successfully tracking containerized AWS applications at scale
Key metrics to monitor for Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS)
Enabling comprehensive monitoring for AWS container environments with Datadog
Disclaimer: The details in this post have been derived from Google Blogs and Research Papers. All credit for the technical details goes to the Google engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Cloud Spanner is a revolutionary database system developed by Google that uniquely combines the strengths of traditional relational databases with the scalability typically associated with NoSQL systems.
Designed to handle massive workloads across multiple regions, Cloud Spanner provides a globally distributed, strongly consistent, and highly available platform for data management. Its standout feature is its ability to offer SQL-based queries and relational database structures while achieving horizontal scalability. This makes it suitable for modern, high-demand applications.
Here are some features of Cloud Spanner:
A multi-version database that uses synchronous replication to ensure data durability and availability even in the case of regional failures.
Use of TrueTime, a technology that integrates GPS and atomic clocks to provide a globally consistent timeline.
Spanner simplifies data management by offering a familiar SQL interface for queries while handling the complexities of distributed data processing under the hood.
Spanner partitions its data into contiguous key ranges, called splits, which are dynamically resharded to balance the load and optimize performance.
Overall, Google Spanner is a powerful solution for enterprises that need a database capable of handling global-scale operations while maintaining the robustness and reliability of traditional relational systems.
In this article, we’ll learn about Google Cloud Spanner's architecture and how it supports the various capabilities that make it a compelling database option.
The Architecture of Cloud Spanner
The architecture of Cloud Spanner is designed to support its role as a globally distributed, highly consistent, and scalable database.
At the highest level, Spanner is organized into what is called a universe, a logical entity that spans multiple physical or logical locations known as zones.
Each zone operates semi-independently and contains spanservers. These are specialized servers that handle data storage and transactional operations. Spanservers are built on concepts from Bigtable, Google’s earlier distributed storage system, and include enhancements to support complex transactional needs and multi-versioned data.
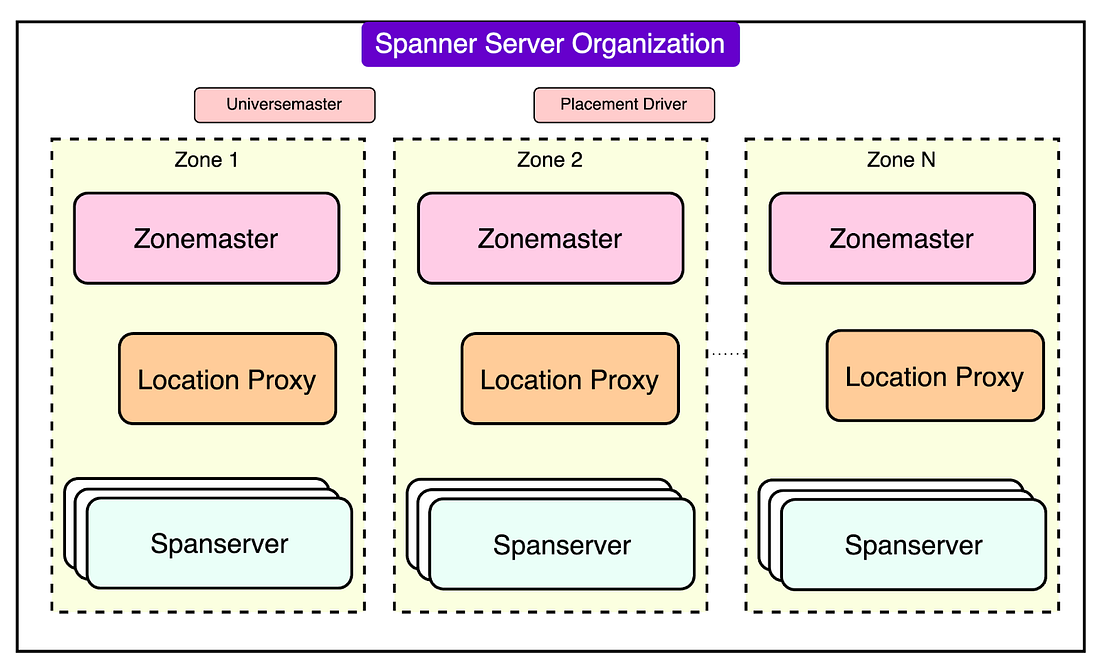 |
Some of the key architectural components of Spanner are as follows:
1 - Data Sharding and Tablets
Cloud Spanner manages data by breaking it into smaller chunks called tablets, distributed across multiple spanservers.
Each tablet holds data as key-value pairs, with a timestamp for versioning. This structure allows Spanner to act as a multi-version database where old versions of data can be accessed if needed.
Tablets are stored on Colossus, Google’s distributed file system. Colossus provides fault-tolerant and high-performance storage, enabling Spanner to scale storage independently of compute resources.
2 - Dynamic Partitioning
Data within tables is divided into splits, which are ranges of contiguous keys. These splits can be dynamically adjusted based on workload or size.
When a split grows too large or experiences high traffic, it is automatically divided into smaller splits and redistributed across spanservers. This process, known as dynamic sharding, ensures even load distribution and optimal performance.
Each split is replicated across zones for redundancy and fault tolerance.
3 - Paxos-Based Replication
Spanner uses the Paxos consensus algorithm to manage replication across multiple zones. Each split has multiple replicas, and Paxos ensures that these replicas remain consistent.
Among these replicas, one is chosen as the leader, responsible for managing all write transactions for that split. The leader coordinates updates to ensure they are applied in a consistent order.
If the leader fails, Paxos elects a new leader, ensuring continued availability without manual intervention. The replicas not serving as leaders can handle read operations, reducing the workload on the leader and improving scalability.
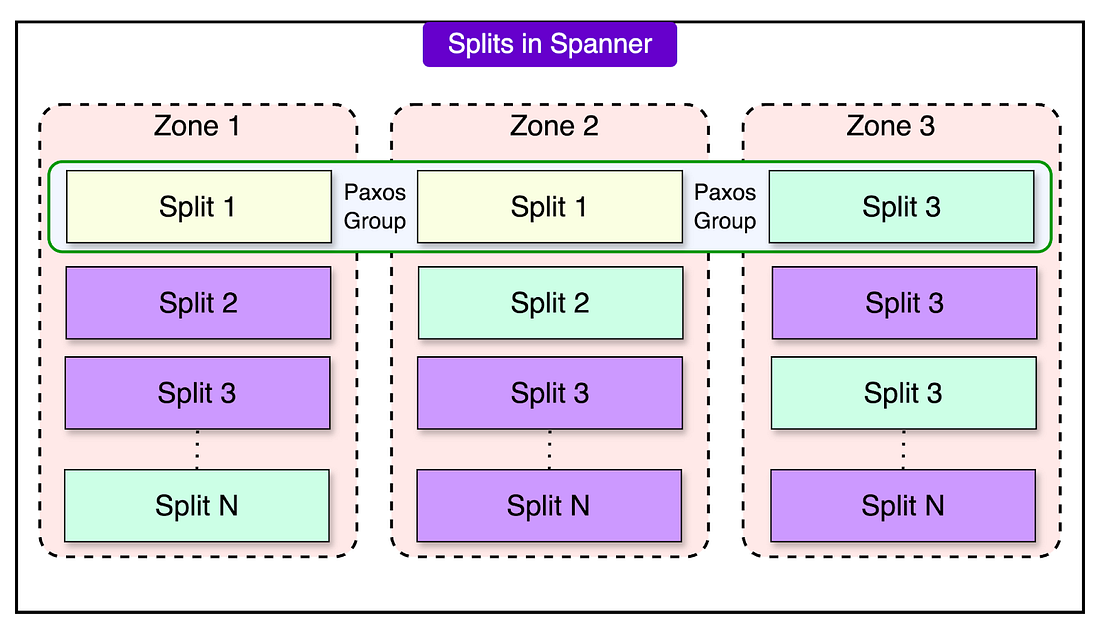 |
4 - Multi-Zone Deployments
Spanner instances span multiple zones within a region, with replicas distributed across these zones. This setup enhances availability because even if one zone fails, other zones can continue serving requests.
For global deployments, data can be replicated across continents, providing low-latency access to users worldwide.
5 - Colossus Distributed File System
All data is stored on Colossus, which is designed for distributed and replicated file storage. Colossus ensures high durability by replicating data across physical machines, making it resilient to hardware failures.
The file system is decoupled from the compute resources, allowing the database to scale independently and perform efficiently.
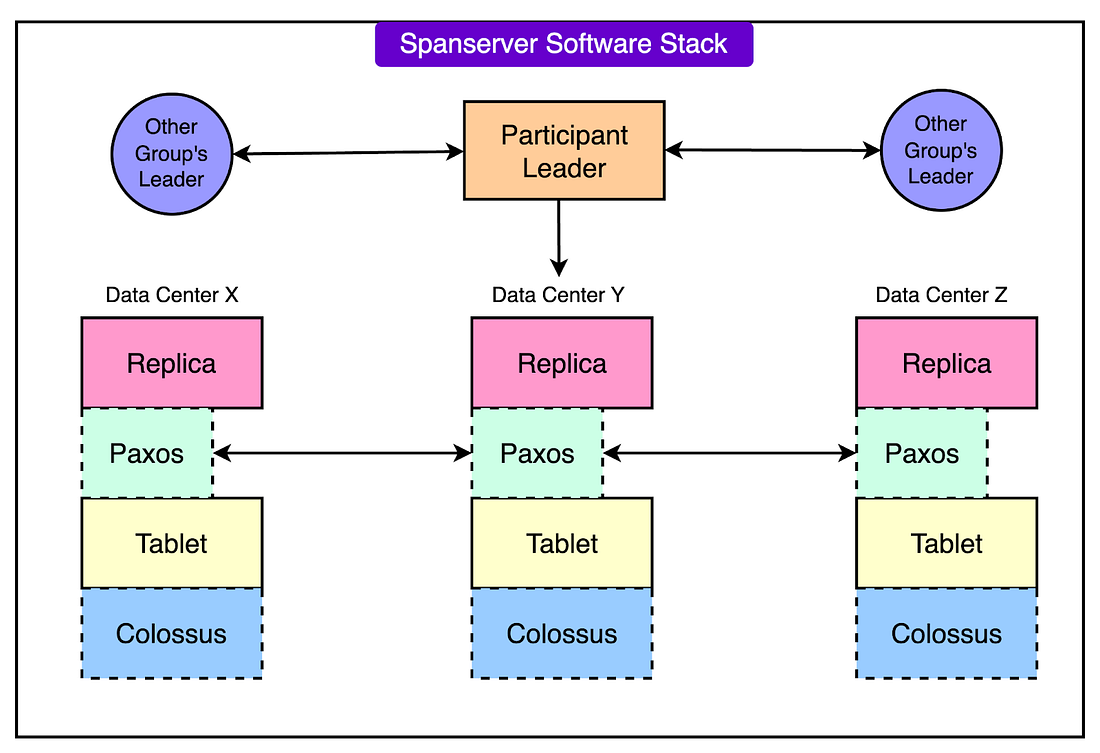 |
Paxos Mechanism in Spanner
The Paxos Mechanism is a critical component of Spanner’s architecture.
It operates on the principle of distributed consensus, where a group of replicas (known as a Paxos group) agrees on a single value, such as a transaction's commit or the leader responsible for handling updates.